

BluelightAI Research Fellowship
At BluelightAI we believe that understanding how AI models work will be a key factor in ensuring that these models benefit humanity. We’re using topological data analysis and mechanistic interpretability to get insights into models’ internal functioning, and building tools to leverage those insights in real-world scenarios. Some things we’ve been working on recently include training cross-layer transcoders for Qwen 3, using CLT/SAE features to train interpretable classifiers, and using SAE features to investigate patterns in model performance.
We’re excited to open a number of research fellowship positions for students, postdocs, or others who are interested in getting deeper into mechinterp and TDA. These will be high-velocity collaborations with BluelightAI team members to make discoveries about how AI models work. These will be remote collaborations—applicants from all around the world will be accepted. If you have experience with TDA, LLM training, or mechanistic interpretability, we’d love to work with you!

Circuit tracing with the Qwen3 Cross-layer Transcoders
A circuit-level analysis of how Qwen3 produces specific predictions.
Cross-layer transcoders (CLTs) were originally developed to help find circuits in large language models. Circuits are collections of components in the model through which we can causally trace the model’s logic as it produces an output, explaining why the model produces the output it does for a given input. For a circuit-based explanation of a model to work well, it should do a few things.
The circuit should be made up of pieces we understand. In our case, these pieces will be groups of CLT features.
The circuit should tell a story. We should be able to identify different steps in the model’s computational process and why those steps make sense to do. For a particular prompt, we will look for computational connections between these groups of features.
Finally, the circuit should let us intervene in the model’s computation with predictable effects. To test this, we will steer groups of features and observe the effect on the model’s prediction.

Introducing Cross-Layer Transcoders for Qwen3
A New Step Toward Understanding How Qwen3 Represents and Transforms Information
Today, BluelightAI is releasing the first-ever Cross-Layer Transcoders (“CLTs”) for the Qwen3 family of models, beginning with Qwen3-0.6B and Qwen3-1.7B. These CLTs make it possible to examine how Qwen3 encodes concepts, propagates information, and composes meaning across its layers.
Alongside the CLT release, we are launching a dashboard to explore the features discovered. The Qwen3 Explorer provides an interactive environment for studying learned features, tracing activation flows, and visualizing the model through Cobalt’s topological data analysis.
Together, these components make Qwen3 one of the most interpretable open-source model families available.

Using TDA and Sparse Autoencoders to Evaluate TruthfulQA
When we used Cobalt to analyze an LLM’s performance on the TruthfulQA dataset, we discovered five distinct failure groups of questions that the model underperformed on.
We characterized them as follows:
fg/1 (questions confusing two well-known figures with the same first name)
fg/2 (questions about geography)
fg/3 (questions about laws and practices in different countries)
fg/4 (pseudoscience and commonly misattributed quotes)
fg/5 (questions that try to confuse fact with opinion)
In this post, we’ll use some more advanced tools from topological data analysis and mechanistic interpretability to go even deeper into the model’s performance and the TruthfulQA dataset. Specifically, we’ll use a set of sparse autoencoders trained on the Gemma 2 model to better understand what the model sees when it looks at the TruthfulQA questions.
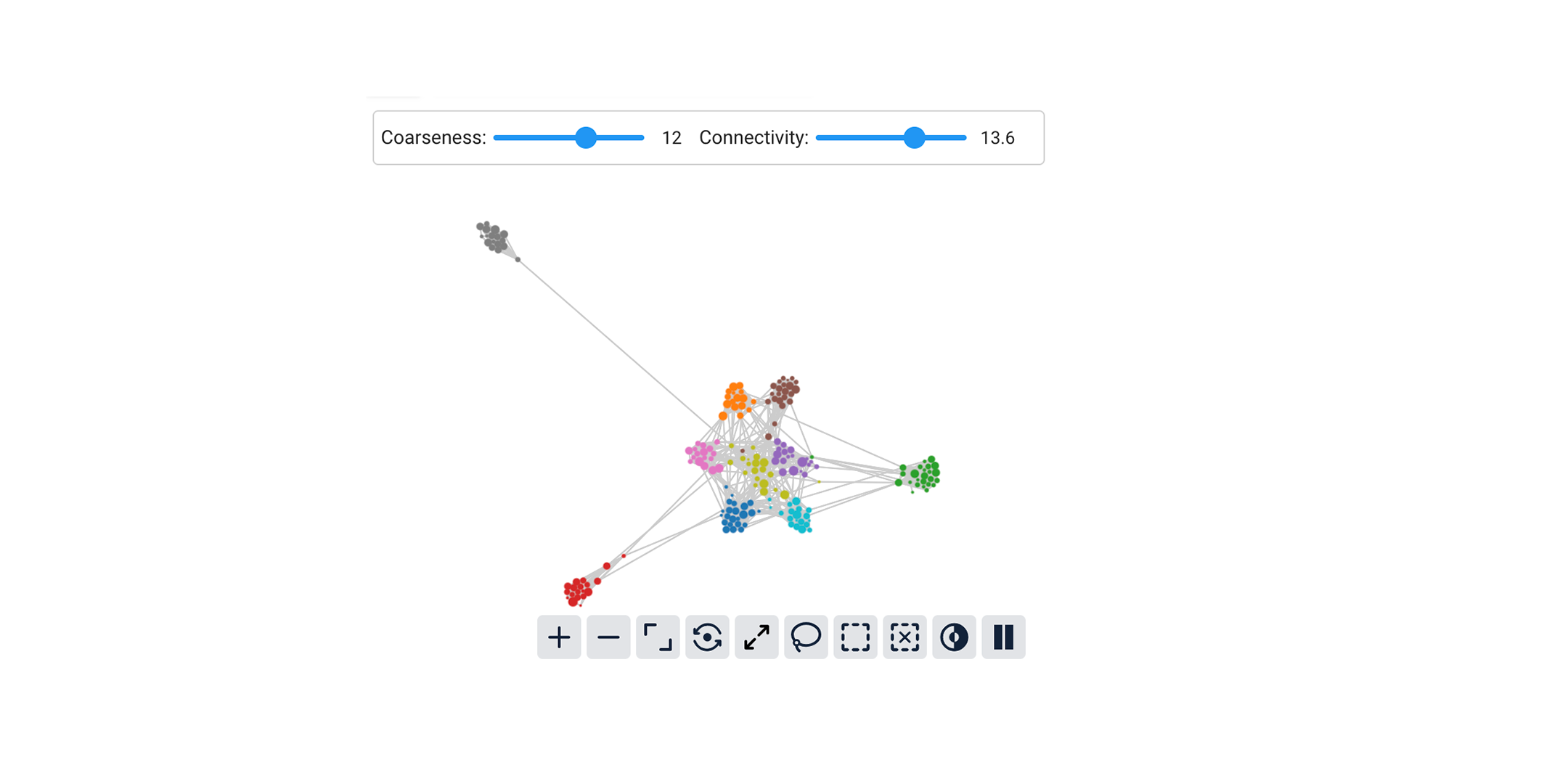
New Release: Cobalt Version 0.3.9
Cobalt Version 0.3.9 is now available. You can install the latest version by running pip install --upgrade cobalt-ai
Features:
Group comparison in the UI now supports a choice of different statistical tests for numerical features.
In addition to the t-test, the Kolmogorov-Smirnov test and the Wilcoxon rank-sum test are supported, as well as a version of the t-test that uses permutation sampling to approximate the p-value instead of the t-distribution.
Workspace.get_group_neighbors() is a new method that finds a group af nearby neighbors of a given CobaltDataSubset. This neighborhood group can also be used as Group B in the group comparison UI.
The graph layout algorithm has been substantially improved and now presents cleaner, easier-to-read graphs. Some configuration options are available in cobalt.settings.

Evaluating LLM Hallucinations with BluelightAI Cobalt
Large language models are powerful tools for flexibly solving a wide variety of problems. But it’s surprisingly common for them to produce outputs that are untethered to reality. This phenomenon of hallucination is a major limiting factor for deploying LLMs in sensitive applications. If you want to deploy an LLM-based system in production, it’s important to understand the types of mistakes it may make, and use this knowledge to make decisions about what model to deploy and how to mitigate risks.
In this post, we’ll see how BluelightAI Cobalt can help understand a model’s tendency to hallucinate. In particular, we’ll identify certain types of inputs or questions where a model is more prone to make errors. Follow along in the Colab notebook!

How to Use BluelightAI Cobalt with Tabular Data
BluelightAI Cobalt is built to quickly give you deep insights into complex data. You may have seen examples where Cobalt quickly reveals something hidden in text or image data, leveraging the power of neural embedding models. But what about tabular data, the often-underappreciated workhorse of machine learning and data science tasks? Can Cobalt bring the power of TDA to understanding structured tabular datasets?
Yes! Using tabular data in Cobalt is easy and straightforward. We’ll show how to do this with a quick exploration of a simple tabular dataset from the UCI repository. This dataset consists of physiochemical data on around 6500 samples of different wines, together with quality ratings and a tag for whether the wine is red or white.