
A New Step Toward Understanding How Qwen3 Represents and Transforms Information.
Today, BluelightAI is releasing the first-ever Cross-Layer Transcoders (“CLTs”) for the Qwen3 family of models, beginning with Qwen3-0.6B and Qwen3-1.7B. These CLTs make it possible to examine how Qwen3 encodes concepts, propagates information, and composes meaning across its layers.
Alongside the CLT release, we are launching a dashboard to explore the features discovered. The Qwen3 Explorer provides an interactive environment for studying learned features, tracing activation flows, and visualizing the model through Cobalt’s topological data analysis.
Together, these components make Qwen3 one of the most interpretable open-source model families available.
Why This Release Matters
Today’s large language models (“LLMs”) perform tasks that would have seemed miraculous just five years ago. They can solve mathematical problems, write arguments across thousands of tokens, and engage in reasoning that spans multiple steps. When you interact with these systems, they work. That said, it’s extremely challenging to explain how they work. This represents a fundamental gap between capability and understanding, between what these systems can do and what we know about how they do it.
Mechanistic interpretability is a developing research field that is seriously working to bridge this gap. Its primary goal is to discover and understand the mechanisms that AI models use to perform tasks. These can range from low-level syntactic tasks like selecting the right grammatical form of a word or formatting text in the expected way to algorithmic operations like addition to high-level decision making like whether to decline a particular request.
Mechanistic interpretability generally investigates representations and circuits inside a model. When a language model reads text, every word is converted into a list of numbers, known as activations, with thousands of numbers per word. These representations are iteratively processed by each layer of the model, getting updated and refined until the model figures out what it wants to say. It’s extremely difficult for humans to look at these arrays of numbers and understand what they mean. Decoding these high-dimensional activations is a top priority.
Cross-layer transcoders are a technique recently introduced by Anthropic that provides a systematic way to decompose these activations into sparse and interpretable features. These features shed light on how models process information, reason about context, and construct meaning.
This approach has already revealed new mechanisms inside other model families. Extending it to Qwen3 broadens the space of models available for mechanistic interpretability work. The smaller Qwen3 variants, specifically 0.6B and 1.7B, are particularly well suited for rapid research iterations. They are inexpensive to run, yet significantly more capable than many of the older models that are often still used as baselines in interpretability experiments.
The CLTs we release today will enable:
- Concept-level understanding of Qwen3’s internal representations
- Circuit tracing that identifies how features influence each other and contribute to the model’s outputs
- Model diagnostics that reveal brittle behaviors and unexpected activations
- More informed adaptation of Qwen3-based systems, guided by mechanistic structure rather than guesswork
These tools provide a higher-resolution picture of the Qwen3 models’ internal operations than has previously been available, helping move the field toward greater transparency and reliability.
What Are Cross-Layer Transcoders?
A cross-layer transcoder is an interpreter model trained to decompose the internal activations of a language model into thousands of sparse features. Each feature ideally corresponds to an interpretable concept or pattern: a syntactic role, a factual association, a contextual cue, or a semantic abstraction the model uses in its internal reasoning.
CLTs work as follows:
- An encoder maps the inputs to every layer of the model into sparse feature activations.
- These activations are used by a decoder to reconstruct the outputs of all future layers.
- Because the reconstruction is routed through sparse features, it becomes possible to analyze how specific features influence later layers and the final model outputs.
This structure allows the model’s computation to be studied in terms of meaningful intermediate concepts rather than opaque, polysemantic vectors.
Contents of the Release
We are releasing CLTs for Qwen3-0.6B-Base and Qwen3-1.7B-Base, available now on Hugging Face, and compatible with the open-source circuit-tracer library.
Each CLT extracts 20,480 features per layer, totaling approximately 573,000 features. They are trained on roughly 750 million tokens drawn from web text, books, code, and mathematical sources. For more details, see our technical report.
The Qwen3 Explorer provides:
- Basic statistics for CLT models and features
- Visualizations of the contexts where each feature activates
- Topological graphs of feature clusters generated with Cobalt
- Tools to take notes on individual features and groups of features
These tools help researchers to explore Qwen3’s internal mechanisms at multiple levels of abstraction.
Topological Analysis Using Cobalt
We used Cobalt to build multiresolution topological graphs from the features identified by each CLT. These graphs reveal the larger-scale structure of Qwen3’s internal representations and make it easier to understand how related features organize and interact.
Cobalt constructs these graphs by identifying neighborhoods of similar features, clustering them at multiple resolutions, and forming weighted graphs that reflect these relationships. We generated separate graphs using encoder vectors, decoder vectors, and coactivation patterns. For coactivation analyses, we applied preprocessing to isolate the largest meaningful component and to divide it into clusters that can be explored interactively.
These maps highlight groups of related features, cross-layer patterns, and communities of coactivating features that correspond to broader conceptual structures inside the model.
Example Features
The features discovered by these CLTs span a wide range of concepts and levels of abstraction. In our experience, the cross-layer nature of these models significantly reduces feature redundancy compared with other unsupervised feature discovery methods, and makes it much easier to find interpretable and interesting features. The topological graphs also make it easy to find related groups of features.
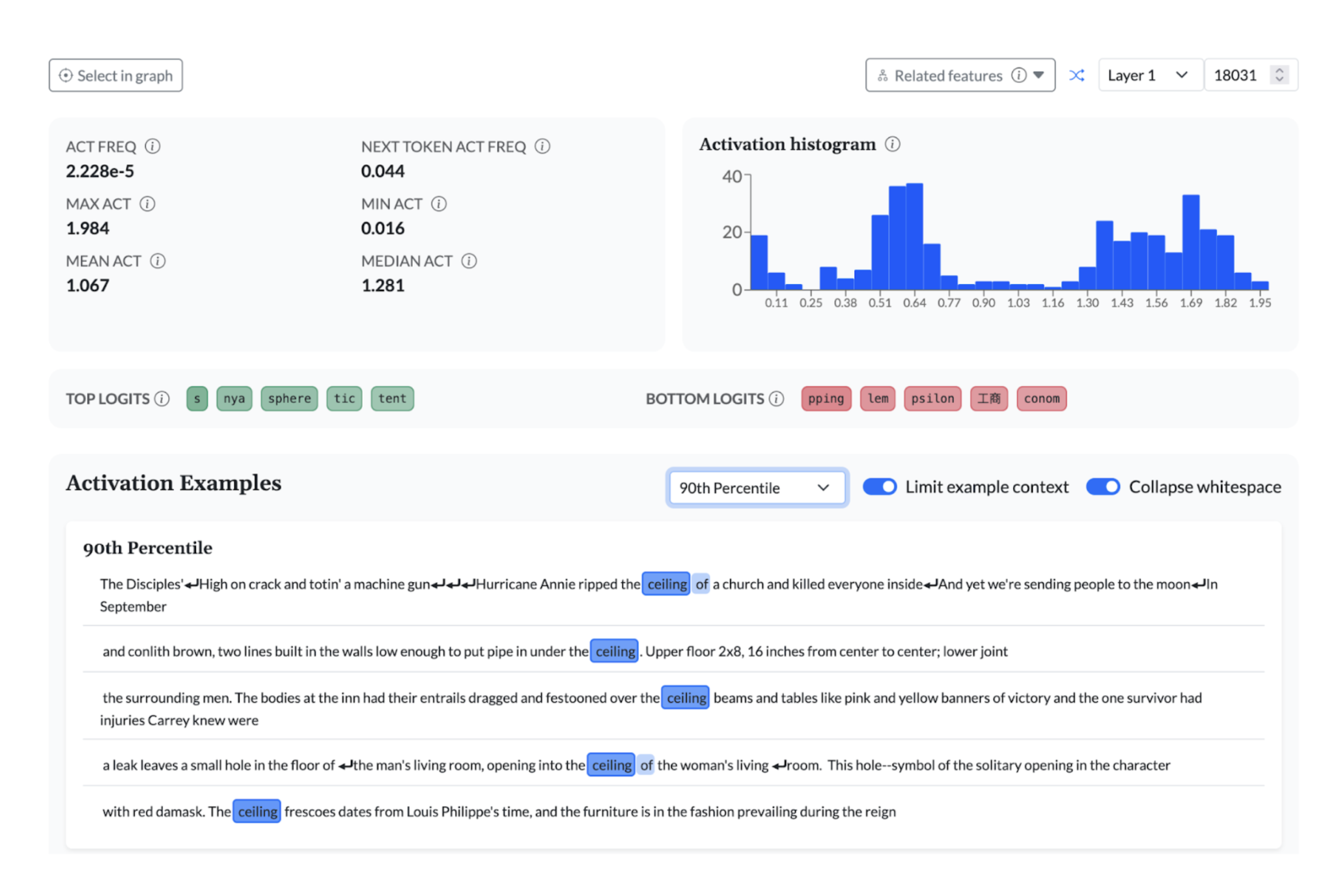
Features in early layers are often focused on a single word or close set of synonyms, like this one that highlights the word “ceiling”:
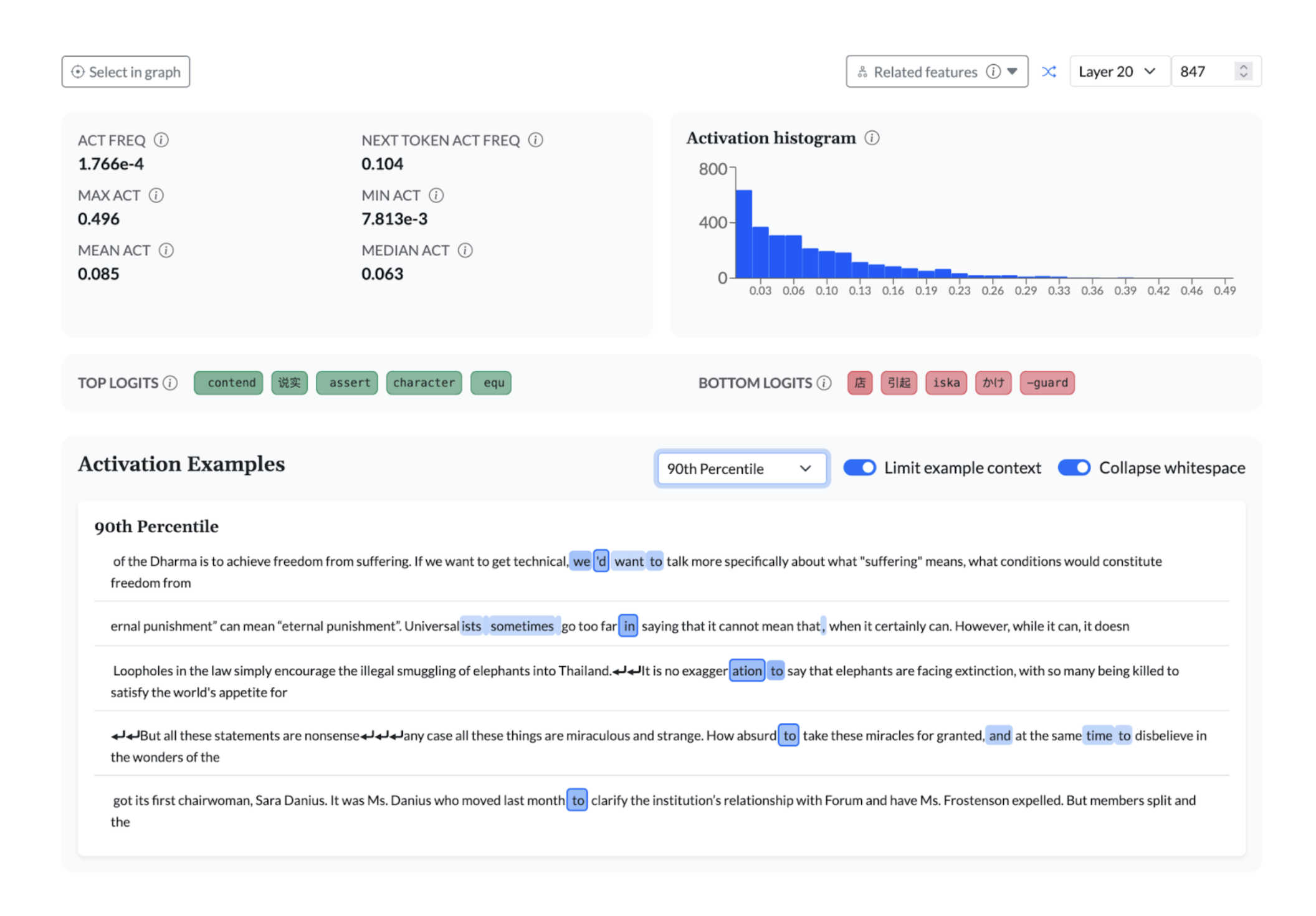
Features in later layers often indicate something about what the model is planning to say next, as with this feature that predicts an upcoming past-tense verb:
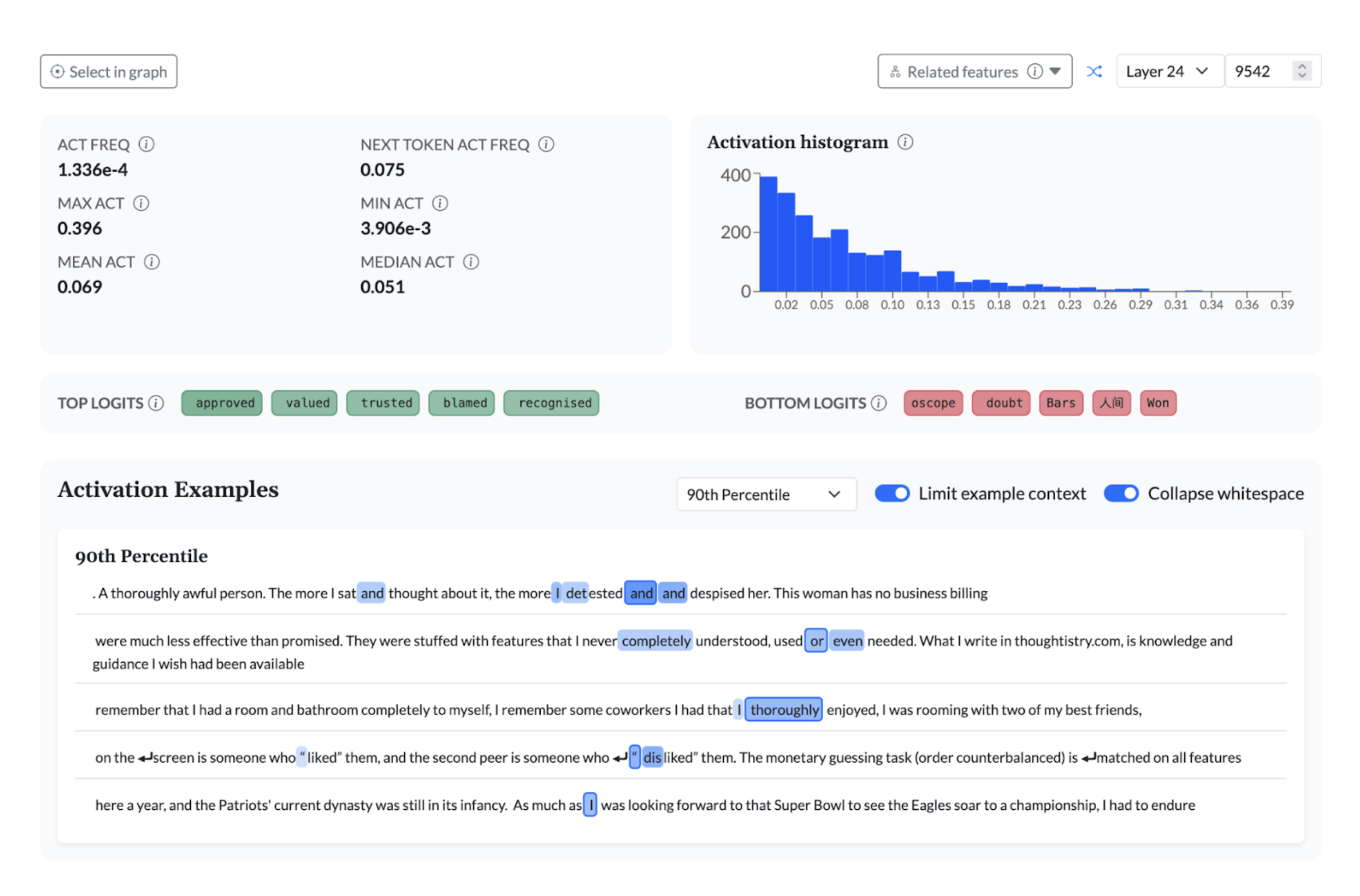
In between, there are many features that capture more subtle and complex concepts, like this one that identifies situations where a critique of a previous argument is occurring:
You can find these features and many more in the Qwen3 Explorer at qwen3.bluelightai.com.
Toward More Transparent Models
Mechanistic interpretability remains an open scientific challenge. These tools do not provide a complete mechanistic account of Qwen3. They do offer a clearer view of its internal computation and provide a foundation for future research.
We hope this release supports the broader interpretability community and contributes to making modern language models more transparent, safer, and more predictable. We’re excited to share more of what we’ve been doing to make models more understandable in the near future.